YOLO v1 Real Time Object Detection
You Only Look Once: Unified, Real-Time Object Detection
Introduce
Object Detection
Algorithm of The YOLO Detection System 其流程主要分為三個步驟 :
- 將影像大小調整至448*448
- 執行卷積神經網路進行物件偵測與分類
- 透過 NMS (Non-max suppression) 方式框出影像中物件之位置,輸出最終結果

Object localization and classification
Object detection 運作步驟 :
- 偵測目標位置(產生物件框)
- 對目標物件進行分類
其演算法架構可分為 one-stage, two-stage.
two-stage: 將步驟1, 2分開執行,輸入之影像先藉由物件偵測產生物件框後,再透過 classification 進行分類。performance 通常較好,若偵測出的物件過多,除非有很強的GPU平行運算,否則運算時間將會慢許多。
e.g. RCNN
one-stage: 輸入之影像透過神經網路同時進行物件偵測與辨識。運算速度較 two-stage 快,但 performance 相對沒有很好,不過後續研究結構的複雜化使其 performance 愈來愈好甚至超越 two-stage。
e.g. YOLO
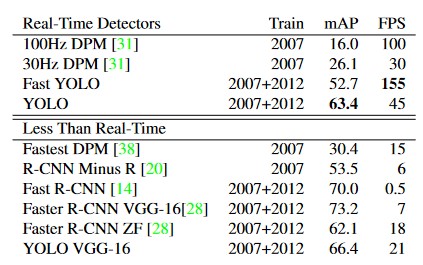
Comparison to Other Real-Time Systems
YOLO - FPS: 45, mAP: 63.4
於 Real-Time Detectors 雖然每秒幀數(FPS)表現普通,不過其對所有辨識種類的平均辨識率(mAP)為最高。
於 Less Than Real-Time 其mAP表現不遜色於其他,且FPS為最高。
| Comparison | Error Analysis |
|---|---|
 |
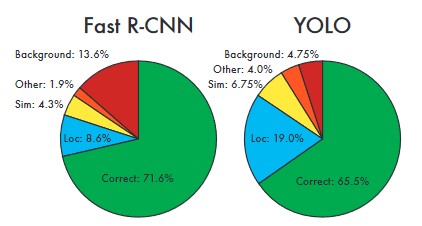 |
IOU
IOU = 交集a / 聯集a,其值介於0~1之間。
一般判斷辨識率以IOU >= 0.5 為基準。
| bounding box | IOU |
|---|---|
 |
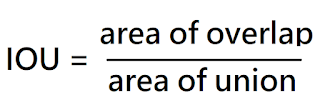 |
AP、mAP
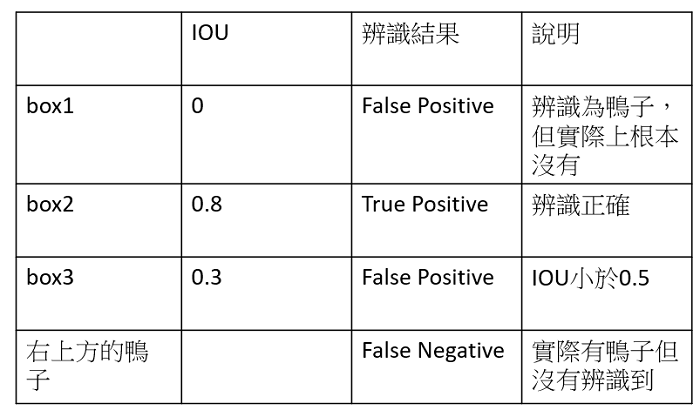
precision: 所有被系統預測為鴨子的結果中,真的是鴨子的比例。
recall: 所有真的鴨子,被系統預測正確的比例。
| predict | result |
|---|---|
 |
 |
| precision | recall |
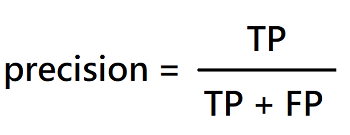 |
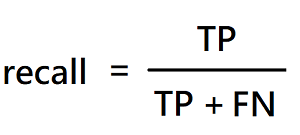 |
AP (average precision): 系統預測該類別時(鴨子)的平均辨識率。
mAP (mean average precision): 系統對於所有辨識種類(鴨子、貓、狗、人、車…等等)的平均辨識率。
Algorithm architecture
Unified Detection
The Model
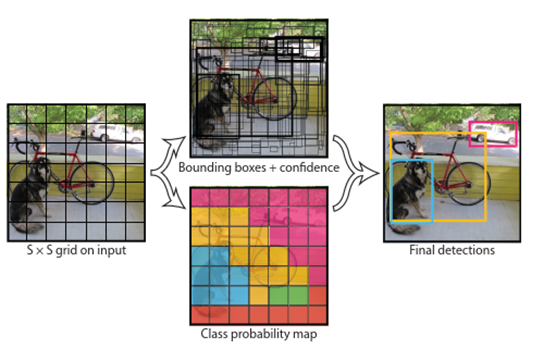
YOLO會將影像分成 S*S 格(grid),每個 grid 有兩個 bounding box 做物件偵測,其一開始偵測到的物件有 7*7*2 = 98個,接著每個 grid 會辨識該物件框所框出之物件所屬的類別,最後採用 NMS 將多餘的 bounding box 濾除。
若 grid cell 包含被偵測的物件中心,此 grid cell 須負責偵測該物件。
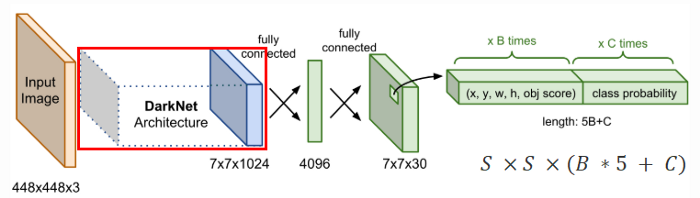
其最後輸出 tensor 的維度 : S * S * (B * 5 + C)
- S : 網格數量
- B : 每個 grid 預測物件的 bounding box 數 (YOLO v1 set B=2)
- 5 : 物件中心 (x, y)、寬高 (w, h)、confidence(是否為物件)
- C : 類別數量(兩個 bounding box 的類別機率)
Confidence
Grid cell 包含目標的機率與IOU相乘。
Pr(Object) : bounding box 裡可能是物件的 probabilities
Pr(Class | Object) : 偵測為物件後,該物件所屬類別的 probabilities
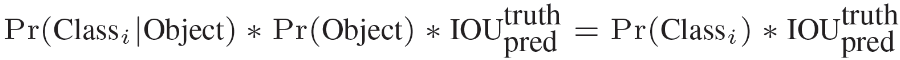
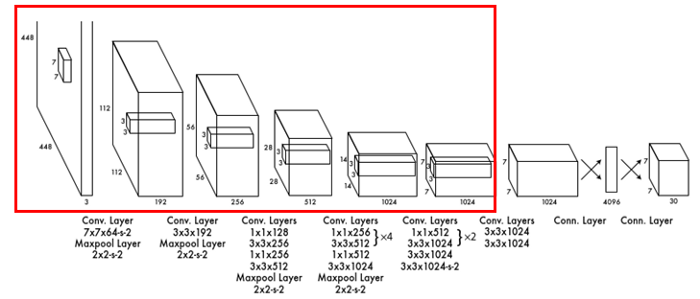
The Architecture
輸入尺寸調整至448*448,以增加提取解析度。
神經網路參考GoogleNet,24層 Conv Layers、2層F.C。
不同的是 YOLO 使用 1*1 卷積(降維)對 3*3 卷積核運算做壓縮,以減少計算參數。取代 GoogleNet 的 Inception modules。
最後輸出 tensor 為 7 * 7 *(2 * 5 + 20) = 7 * 7 * 30
C = 20,使用 PASCAL VOC 資料集,有20種類別。
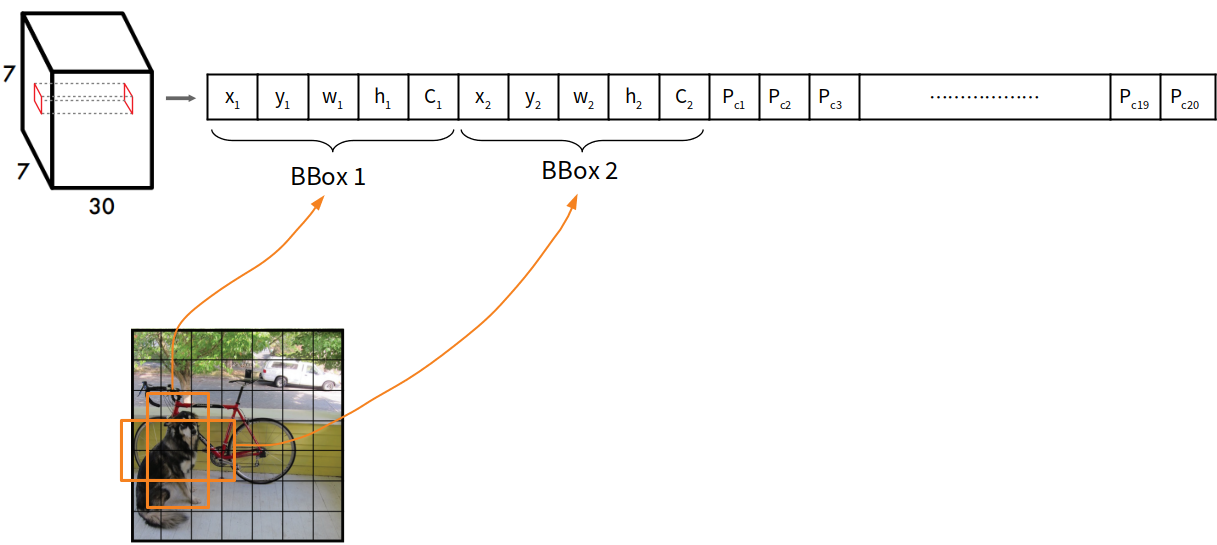
Bounding box 四個位置值為正規化數值 :
(x, y, w, h) = bbox(x, y, w, h) / 原影像(x, y, w, h)
Activation function
Activation function 採用 leaky rectified linear activation (leaky ReLU):
ReLU 會使部分神經元輸出為0,以解決 Overfitting,但有些神經元可能無法被激活(Dead ReLU Problem),因此採用 Leaky ReLU 不增加計算複雜度,提升模型的學習能力。
ReLU 是將所有負值皆設為零;Leaky ReLU 則是將負值乘上非零斜率。
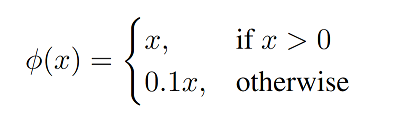
除了輸出層使用 linear activation,其他皆使用 leaky ReLU。
Training
前20層 Conv Layers 是以大型 dataset(ImageNet) 進行 pretrain(特徵提取),因此不修正此處權重。
Pretrain 完成後,再接上隨機權重的4層 Conv Layers(分類器)、2層 F.C。
| Inference |
|---|
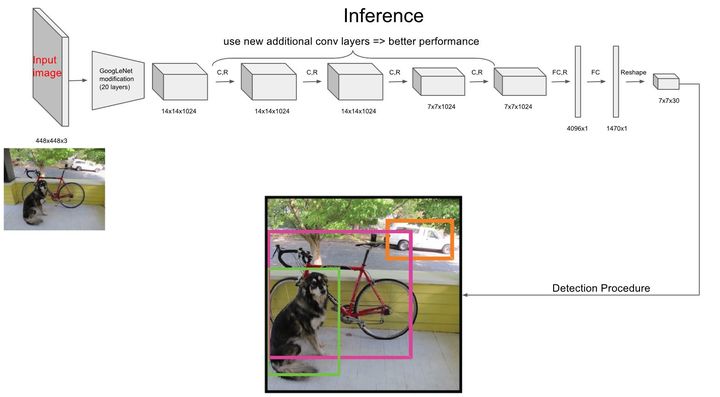 |
| Detection Procedure |
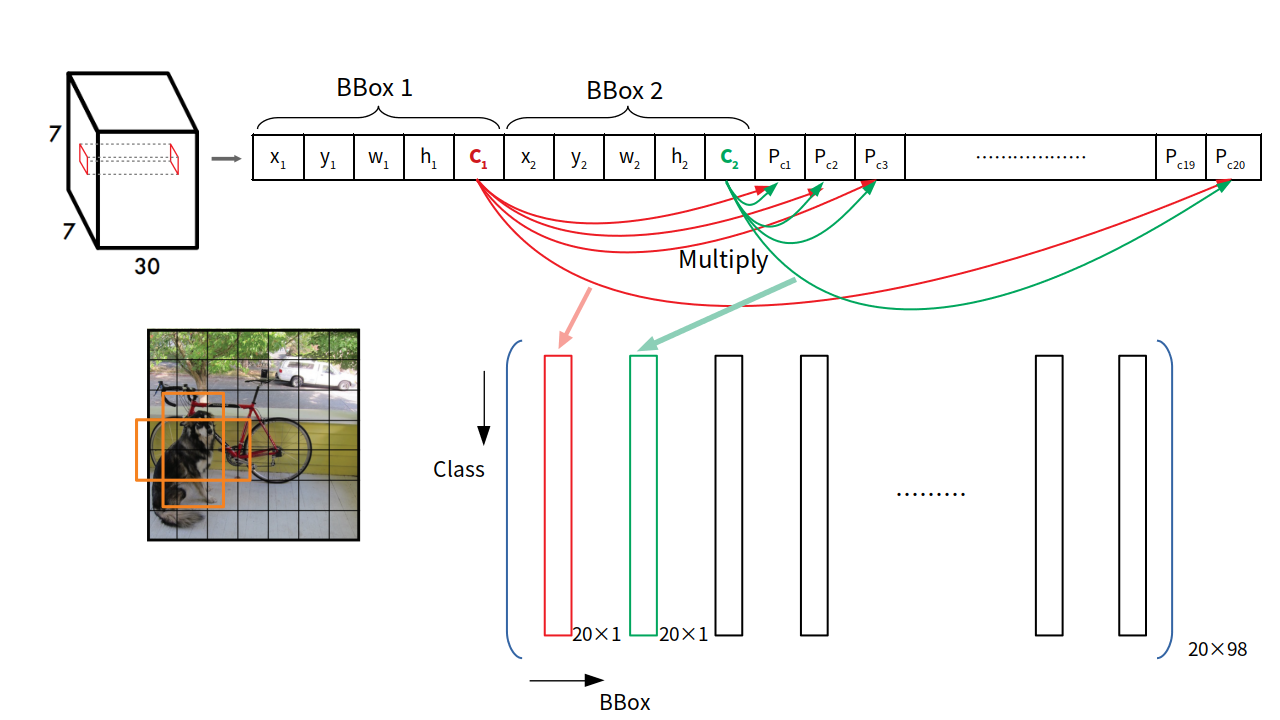 |
最後輸出層進行 detection procedure 時,以Grid 包含兩個 bbox 的 confidence 乘上 Pr(Class),形成評估 bbox 的指數。
Loss Function
採用平方誤差和 (sum-squared error) 做 loss function。
誤差有分類誤差(class error)、邊界框定位誤差(localization error)。
沒有物件的邊界框其 confidence 很低,會將最後指標推向幾乎等於0,導致誤差梯度過大,使整個損失函數被沒有物件的邊界框主導,造成損失不穩定且難以訓練好。
因此誤差除了分類與邊界框定位外,還將有無包含物件的邊界框分開計算,且給予不同權重。
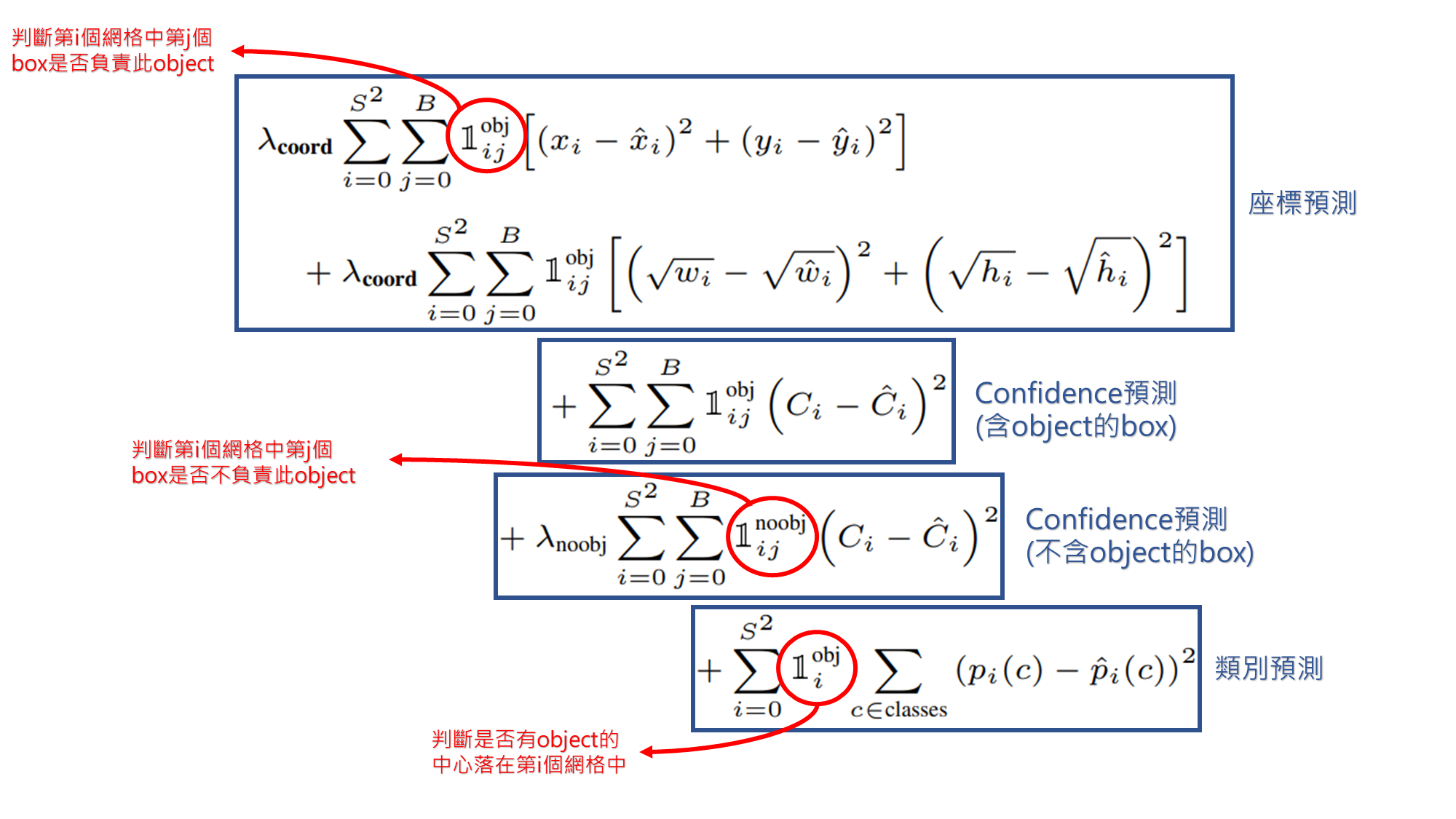

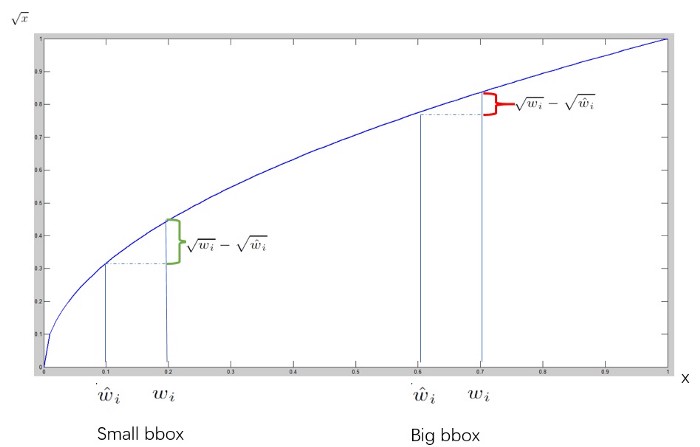
w、h 取平方根 : bbox 的大小對 bias 的影響比例不同,因此取平方根以降低 bias。
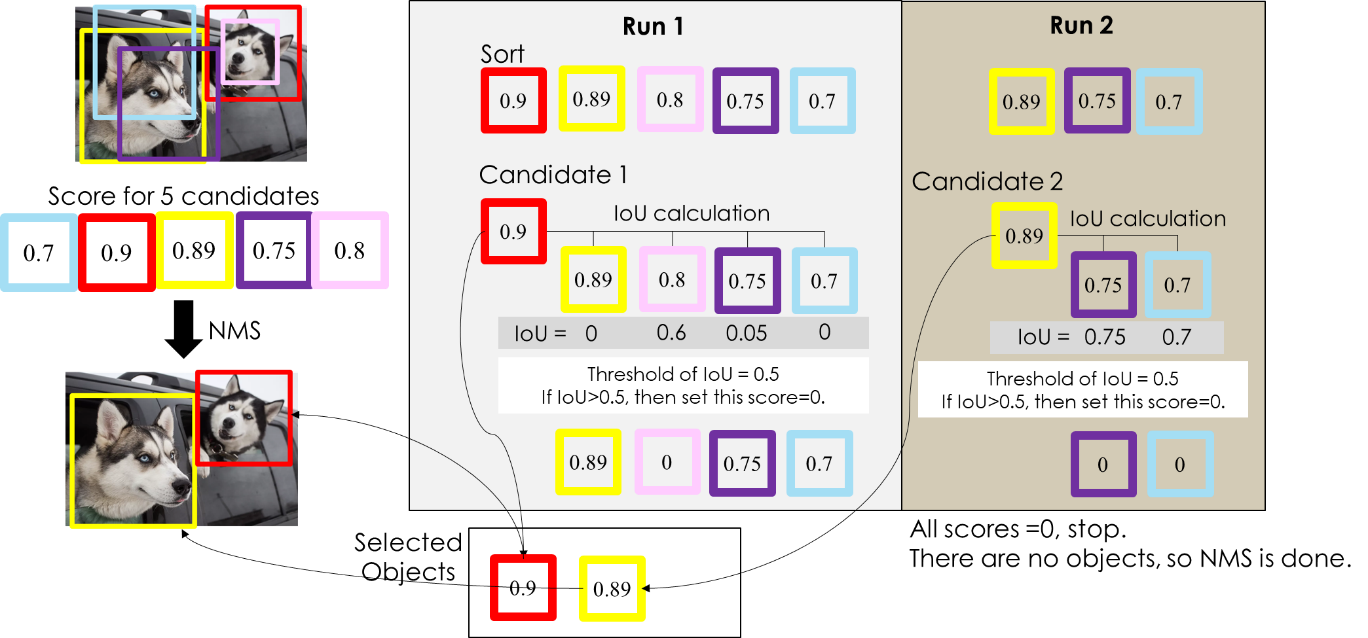
NMS (Non-max suppression)
物件偵測時一個物件可能被很多物件框選中,因此採用 NMS 將多餘的物件框濾除。
- 將 confidence 很低的 bbox 去除,並選出 confidence 最高的 bbox 加入”確定是物件集合” (selected objects)
- 其他 bbox 與選出的 bbox 計算IOU,若 bbox 的IOU結果大於設定好之閾值,其 confidence 會設定為0
Repeat 1、2 步驟直到沒有 bbox 的 confidence > 0,selected objects 為最後結果,NMS結束。
Conclusion
YOLO v1 的速度較 two-stage 模型快上好幾倍(45 fps),且 mAP(63.4) 也比 R-CNN 好很多。
但其也有不少缺點 :
- 每個格子只預測兩個框,且一個框只有一個分類,因此對於群體的小物件偵測能力不佳 (e.g. 一群鳥)。
- 由訓練資料學習辨識與邊界框,對於新的、長寬比不常見之物件難以偵測。其他演算法 e.g. SSD (sol: data augmentation)。
- 經過多個降維,在特徵解析度粗糙的 feature map 上預測邊界框,其泛化能力差(對新數據的適應能力)。
- 於loss function上,邊界框定位誤差為影響預測效果的主因,bounding box 的大小在 loss 的反應上不佳,小的 bbox 對 IOU 影響較大。
Reference
License: Copyright (c) 2021 CC BY-SA 4.0 LICENSE